「Agentic AI Dev Note」 Observing Agent Quality with Evaluation
Across Part 1 and Part 2 of this 「Agentic AI Dev Note」 series, we made our agent operable in the cloud. Now it’s time to check whether that agent actually behaves the way we expect. There are three ways to measure an agent’s quality.
- Code quality: Most of it can be verified with unit/integration/e2e tests. The same input produces exactly the same output, so it can be verified precisely.
- System quality: Measured through runtime error rates, latency, dependency failures, and the like, via alarms and monitoring. Canary tests can monitor system quality too.
- LLM response quality: Measures whether the LLM produced the expected answer to the user’s input.
But how do you guarantee the response quality of a non-deterministic LLM, where the same input can yield a different output every time? For the first two, the same input gives the same output, so you can prove it is “correct.” LLM responses, however, cannot be proven. And if you can’t prove it, the only option left is to observe it: watch the trend of behavior instead of any single correct answer. This post focuses on that.
1. Langfuse - Trace & Score (the infrastructure of observation)
To observe, you first need a record (a trace). A Trace is a single execution captured as a span tree (which prompt, which tools/searches, which response). A Score is a value attached to that trace (a single trace can carry multiple scores). Thinking back to the distributed containers of Part 1, no matter which container received the request, the traces have to pile up in one place.
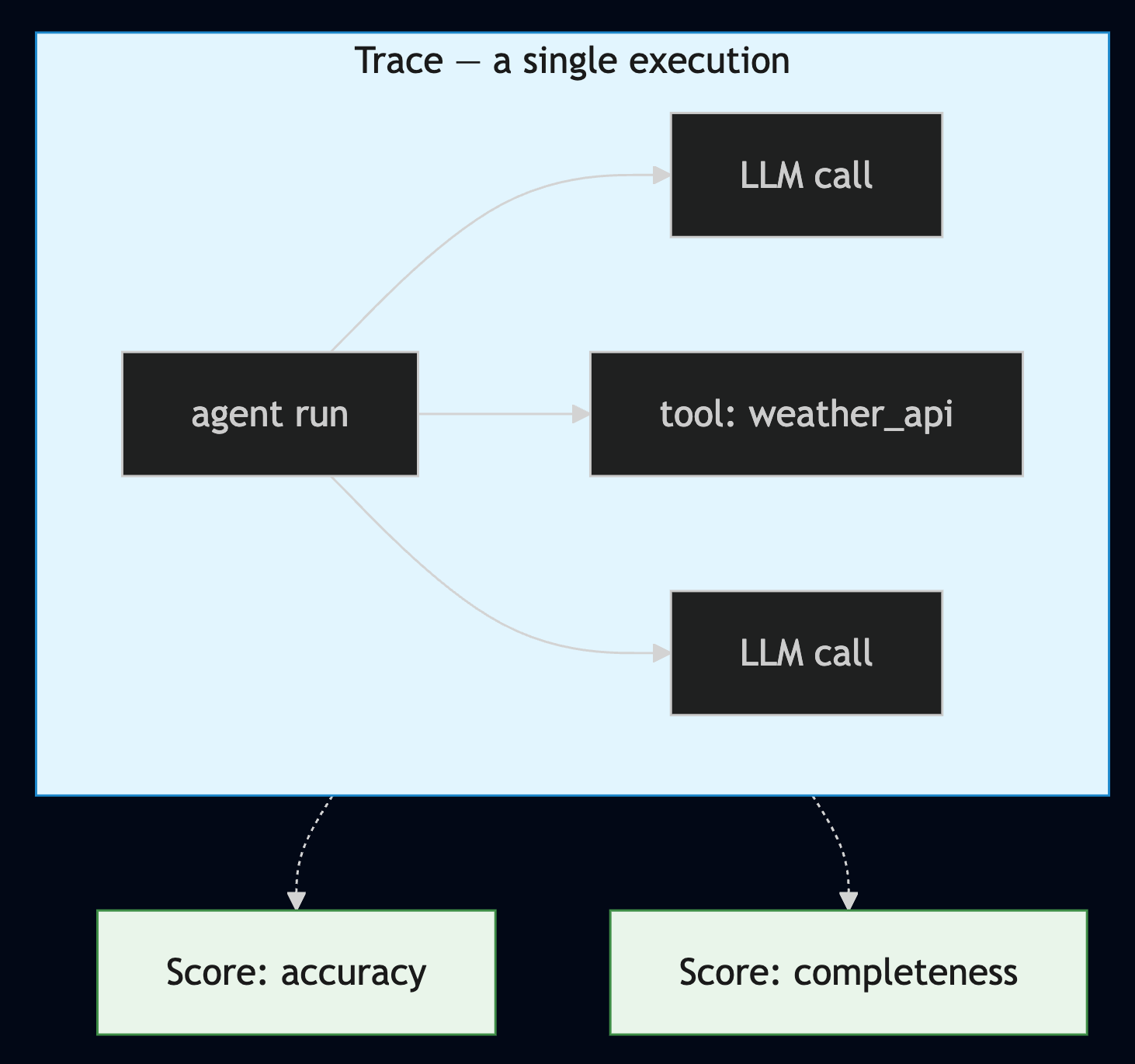
Langfuse handles this, among many other features. It collects the traces the agent emits, lets you view scores, and lets you build dashboards to track trends.
2. LLM as Judge (a Judge that resembles a human)
Before building an LLM Judge, a human first creates an answer key through Ground Truth. This is essentially labeling a set of question and answer pairs. For example, to the question “What are the ingredients of kimchi?”, the response “Making kimchi requires napa cabbage, salt, chili powder, and so on” gets 100 points. The response “Kimchi is a traditional Korean food,” true but not actually answering the question, gets 10 points. This data becomes the basis for building the rubric of a human-like LLM Judge.
Now, using this Ground Truth data, we design the rubric. We must specify the criteria by which a response is scored: does it directly answer the question (relevance), how does it handle dangerous queries (safety), is the answer complete (completeness), and so on. And we have the Judge output not just a score but also the reason for that score, so that when a score drops, we can trace back to what went wrong.
# Rubric example: completeness (does the answer fully cover what was asked?)
# Imagine a recipe chatbot. The Judge outputs one of 0.0 / 0.5 / 1.0 with its reason.
1.0: Covers every key element the question requires (e.g., ingredients, steps, and timing).
0.5: Answers the core but omits a meaningful part (e.g., lists ingredients but skips the steps).
0.0: Misses the question or omits most of what was required.
Whether it’s the human-assigned 100/10 points or this rubric’s 0.0 to 1.0, each criterion uses a different scale, so for comparison everything is normalized to a 0-1 range. Take every score in this post as a normalized value.
The Offline and Online Eval that follow are both performed by this LLM as Judge. But there’s one thing to note. The Judge doing the scoring is also an LLM, so there’s no guarantee it scores like a human from the start. So we run the rubric-equipped Judge over the same question and answer set, then place its scores side by side with the human-made answer key. We refine the rubric until the two are close enough. Only after this process can we trust that this Judge produces scores similar to a human’s.
Now, with this LLM as Judge, we hold a powerful weapon: the ability to score thousands, millions, even hundreds of millions of traces, something no human could ever do. Whether you use Langfuse’s built-in features or generate and upload scores with a custom LLM Judge, once you have Traces and Scores, the groundwork for evaluation is complete.
3. Offline Eval (synthetic data)
You write the expected inputs in advance. These can even be data generated by an LLM. What matters is measuring whether, for the same input, the response always delivers the same quality, however the wording differs each time. Because the input is fixed, if the score drops, what changed is usually something I changed: code, prompt, or model. (Since an LLM is non-deterministic, a single response’s score can fluctuate, so the verdict is based not on one case but on the average and pass rate across the scenario set.)
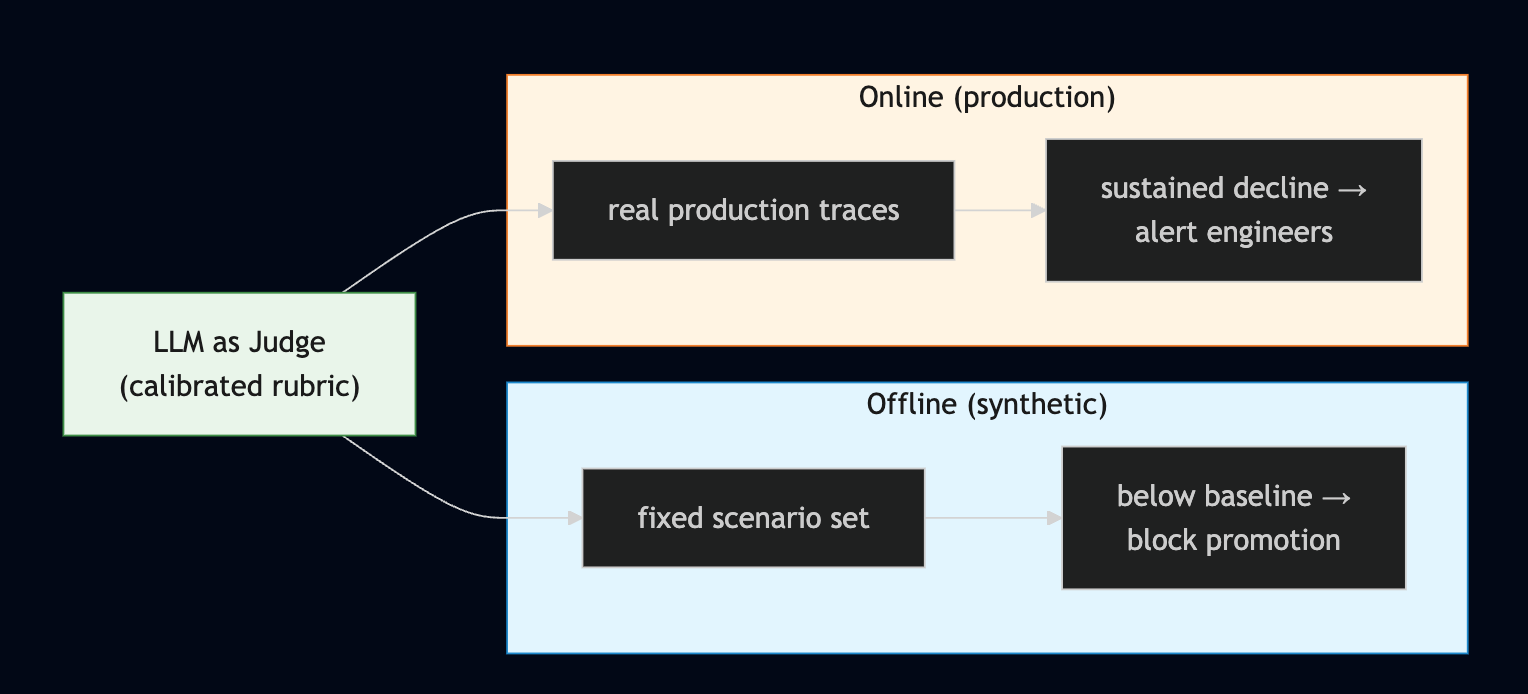
Because of this property, we built this Offline Eval mechanism as the pipeline’s Gate Eval. Every time code or a prompt changes in the pipeline, the Eval runs, and if a significant quality drop is detected, promotion to the next stage is blocked. In other words, it detects changes in LLM responses caused by code and prompt changes, before deployment.
4. Online Eval (production data)
Reality doesn’t move as predictably as this. Unexpected inputs can come in, and there’s no guarantee that the system or the LLM you call is always healthy. Above all, even without changing a single line of my code, a response can shift due to nothing more than a model vendor’s silent update or a change in external search results. Offline Eval can’t catch such changes, because those inputs were never in the scenario set in the first place. So we score actual production data and use it as monitoring for the production environment.
For example, suppose a user asks a food-recipe agent “how to make tacos,” and it unexpectedly answers “Kimchi needs to ferment for several months.” Our LLM as Judge would score this trace 0 by its rubric. Given the nature of LLMs, a slip once or twice is possible. But if this keeps happening, it’s a serious problem. Engineers need to act quickly.
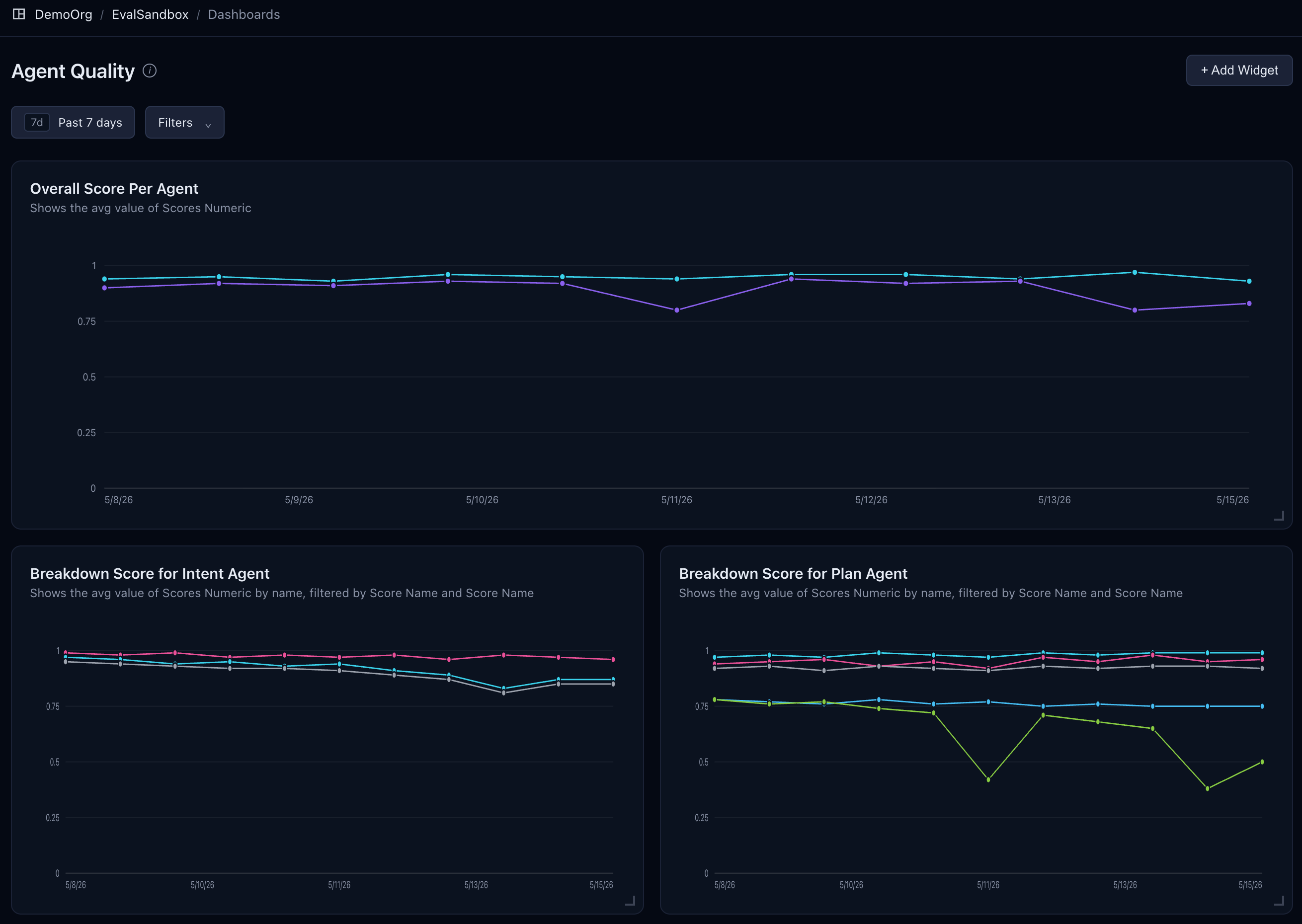
So Online Eval adds continuity. It periodically watches the traces in operation, attaches scores, and posts them to a dashboard. And when needed, it sets alarms so engineers can look in right away. But since a single failure is noise, the alarm should fire only when the decline persists.
Offline and Online ultimately use the same LLM Judge. The only difference is what that Judge looks at. One is the fixed questions I control, the other is the real traffic I cannot. That’s why neither can stand in for the other.
Closing
Through three parts of 「Agentic AI Dev Note」, we now hold a powerful set of tools for operating an agent in the cloud. We covered the stateless container for building the agent’s runtime into a distributed system (Part 1), the separation of the memory layer (Part 2), and the Evaluation that observes the quality of a non-deterministic LLM (Part 3). We can keep it running, let it remember, and watch whether it answers well.
Now only one thing remains.
What does your agent do?