「Agentic AI Dev Note」 Managing Agent Memory in a Distributed Systems
In Part 1, we discussed stateless containers for running Agents in a distributed system. However, the Agents we interact with seem to behave statefully. When a user asks an Agent a question, it answers, and as the conversation progresses, the Agent maintains the context of previous discussions. To achieve this, the system is designed by separating the request processing area from the memory area, fetching the conversation history from memory whenever needed.
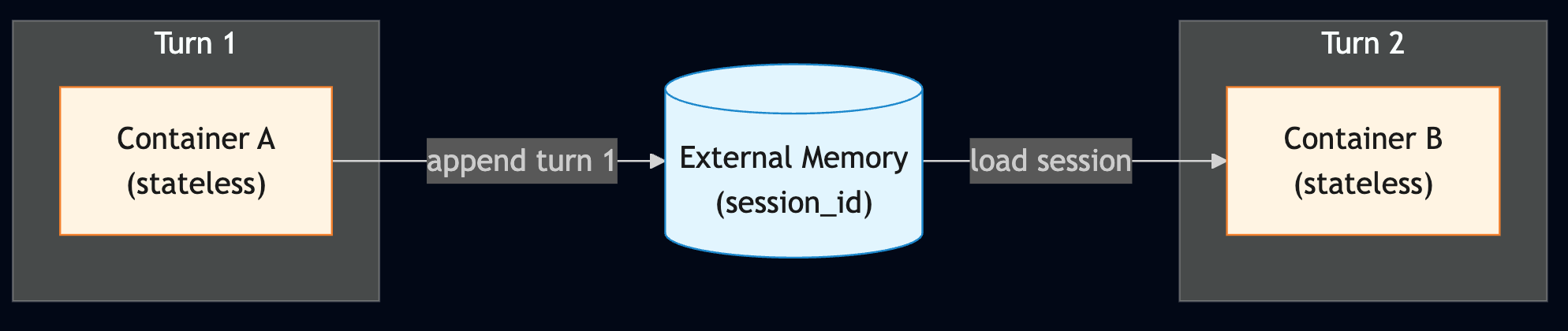
Now, where to place that memory, how to handle memory store failures, and how long to retain it when conversations get long all become subjects of management.
Agent Memory
This is a familiar concept. In standard system architecture, we have traditionally separated Compute into servers and Memory into databases. We approach Agent development in the exact same way. Agent development toolkits like Strands Agents support injecting external memory into the Agent object. Going down to the infrastructure level, AWS’s AgentCore, for example, also provides Runtime and Memory as separate components.
In other words, the session that we glossed over in the single line messages=session.messages at the end of Part 1 is actually an external object read via an identifier from a store outside the container. Expressed in pseudocode, it looks like this:
def handle_request(request):
# Load conversation from external memory
session = conv_store.load(request.session_id)
# Fresh Agent per request, memory injected
agent = Agent(
client=get_llm_client(), # cached (Part 1)
messages=session.messages, # injected from external memory
)
result = agent.run(request.message)
conv_store.append(request.session_id, result) # write back
return result
The Client simply reuses what is cached at the module level. What has changed is injecting session.messages, read from the external store, when creating the Agent object. Once the response is complete, the new turn is appended back to the store. The container starts clean and ends clean, and the continuity of the conversation is maintained outside of it.
Conversations are session-based. Even for the same user, if the session changes, it starts as a new conversation. However, it is natural for a user’s general information across sessions, such as their name, age, or the ‘memory’ feature in ChatGPT or Gemini that transcends sessions, to be stored permanently. If both are placed in a single store, their retention periods, access patterns, and costs will conflict. You would end up paying permanent storage costs for conversation logs that only need a 30-day retention, while user information that should be kept permanently might be wiped out by a retention policy.
Therefore, Agent memory is divided into two tiers.
| Area | Location | Lifecycle |
|---|---|---|
| Conversation memory (Session) | External managed memory (e.g., 30d retention) | Session-based |
| Long-term memory | KV Store | Permanent |
Inside the container (orange) is empty. The two external stores (blue and green) are separated according to their lifecycles, and the Agent calls both with the necessary identifiers on every request.
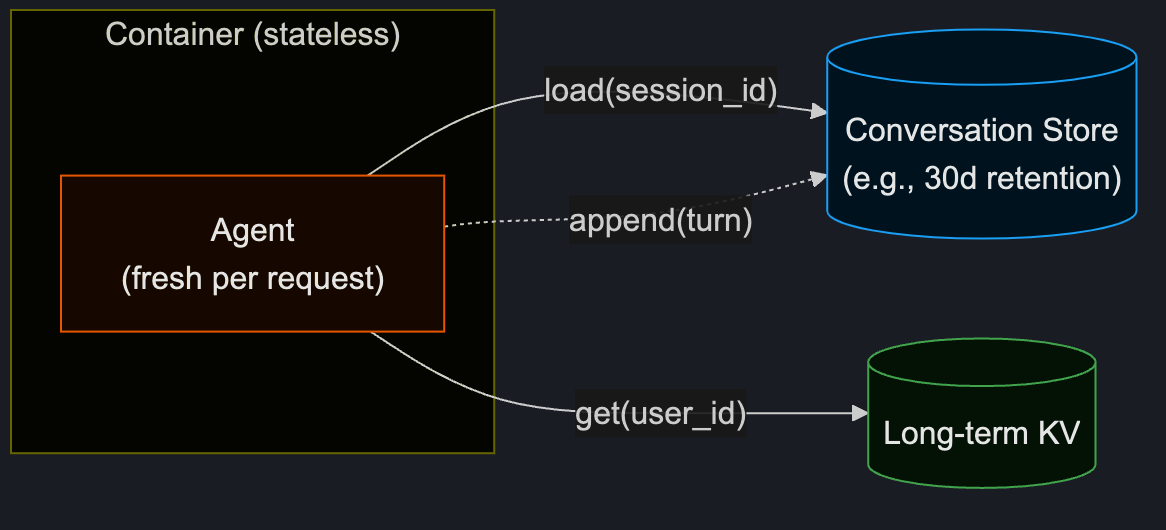
Since long-term memory is not significantly different from a traditional Key-Value store, this post will focus on conversation memory.
Conversation data looks roughly like this:
{
"session_id": "s-abc123",
"user_id": "u-42",
"messages": [
{"role": "user", "content": "I'd like my steak medium, how long will it take?"},
{"role": "assistant", "content": "For a 2.5cm thickness, about 3 minutes per side..."},
{"role": "user", "content": "What about medium rare then?"}
],
"updated_at": "2026-05-15T10:32:00Z"
}
The price of stateless compute is the responsibility to design exactly where and how to keep memories. The amount of space we left empty in the container in Part 1 directly translates to an increased amount of things to handle externally.
Building a Resilient Memory System
The conversation store can also experience failures, and from Compute’s perspective, this is an external dependency. It could be throttled, encounter a temporary internal 5xx error, or suffer a brief network disconnection. In a distributed environment, this happens all the time.
The problem is that memory is called on every request. The two calls conv_store.load() and conv_store.append() in the previous section’s code represent exactly that. If either throws an exception immediately upon hitting a single throttle, the user sees “No Response”. The main request doesn’t even get to attempt the LLM call. A memory failure directly becomes a service failure.
However, an entire service doesn’t need to die just because one Agent conversation log failed to save to memory. The user wants an answer, and that answer comes from the LLM. Missing a single write is merely the cost of a slightly degraded quality in the next turn; it is not a reason to fail the current turn.
Therefore, write failures are suppressed. If an exception occurs during the append call, we do not halt the main request. We simply log it and proceed. On the other hand, read operations are left as is. A broken read is a signal that something major is wrong with the memory store. If we fall back to an empty history, users will keep receiving answers without context, and the operations team might not notice for a while. Failing fast ensures that the signal surfaces immediately.
Instead of scattering try/except blocks all over the calling code, let’s consolidate them in one place using a wrapper class. The caller simply invokes memory.load() and memory.append() as usual, unaware of the isolation.
class ResilientMemory:
def __init__(self, backend):
self._backend = backend
def load(self, sid):
# Read passes through — failure here is a real signal.
return self._backend.read(sid)
def append(self, sid, turn):
# Write is best-effort — losing one turn is cheaper than losing the response.
try:
self._backend.append(sid, turn)
except Exception as e:
log.warn("memory_write_suppressed", sid=sid, err=type(e).__name__)
However, swallowing the error shouldn’t be the end of it. A suppress is a quiet degradation of quality. The user receives an answer, but multi-turn consistency subtly drops. One or two occurrences might be an acceptable cost, but if they accumulate over minutes, that is a real outage. Therefore, we must make these swallowed errors visible.
log.warn("memory_write_suppressed")
└─ Metric Filter
└─ Counter: MemoryWriteSuppressed
└─ Alarm: 10+ occurrences in 5 minutes → trigger
We count structured logs as metrics and trigger an alarm if they cross a threshold over a certain period. Temporary network glitches or one-off throttles are buried, while only persistent failures surface as alarms. This separates everyday occurrences from genuine outages.
Protecting the Context Window
An Agent’s context window is limited. For instance, Claude Sonnet 4.6 supports 200K tokens, and Opus 4.7 supports 1M tokens. If the conversation history exceeds this limit, the Agent cannot respond. This is a service failure.
Therefore, we must trim the amount going into the prompt. There are two commonly used methods:
- Last-K turns: Only the most recent K turns are loaded into the prompt. It is simple, and the cost is constant. Older context is lost.
- Compaction: Older turns are summarized into a single block using an LLM. This preserves some of the long context, but it requires an additional LLM call for the summary, and the quality of the summary directly affects the quality of the answer.
The choice is a trade-off depending on the use case. However, there is one common rule to follow: write saves everything, and the cutoff is only applied at the time of the read. Everything is kept in the store, and only the amount entering the prompt is trimmed.
Conclusion
So far, we have briefly explored how to manage Agent memory in a distributed environment.
- Where to keep it: Outside the container, not inside. Conversation memory goes into a session-based external store, and long-term memory goes into a persistent KV store. Different lifecycles require different containers.
- When failures occur: Suppress write failures and let the main request keep rolling. Make sure swallowed errors are made visible so they trigger an alarm if they accumulate. Leave reads as they are so genuine failure signals aren’t delayed.
- When conversations get long: Trim only the amount going into the prompt. Keep it simple with Last-K turns, or preserve some context with compaction. The full history remains in the store.
Now, it is time to verify if the Agent configured this way is operating correctly.
Traditional IT services have their behavior determined by code. Same input, same output. Thus, most scenarios can be verified through tests (unit, integration, e2e). However, the LLM, which is the core of the Agent, is inherently non-deterministic, meaning the response varies every time even with the same prompt. Its behavior changes even without altering the code.
In the next chapter, we will cover Agent Evaluation to see how to observe the behavior of such Agents.