「Agentic AI Dev Note」 Developing and Operating Agents in a Distributed Systems
We imagine it like this: a user sends a request to an Agent, an Agent floating somewhere processes the request, and returns the result. In the big picture, this is correct. However, a real distributed environment is not quite this simple.
When a request comes in, a container is provisioned, the Agent inside it processes the request, and if it remains idle for a certain period, the container is destroyed. The next request might be received by a completely different container. This is a mechanism for the scalability and efficiency of a distributed system. If traffic increases, containers must be scaled up; if it decreases, they must be scaled down.
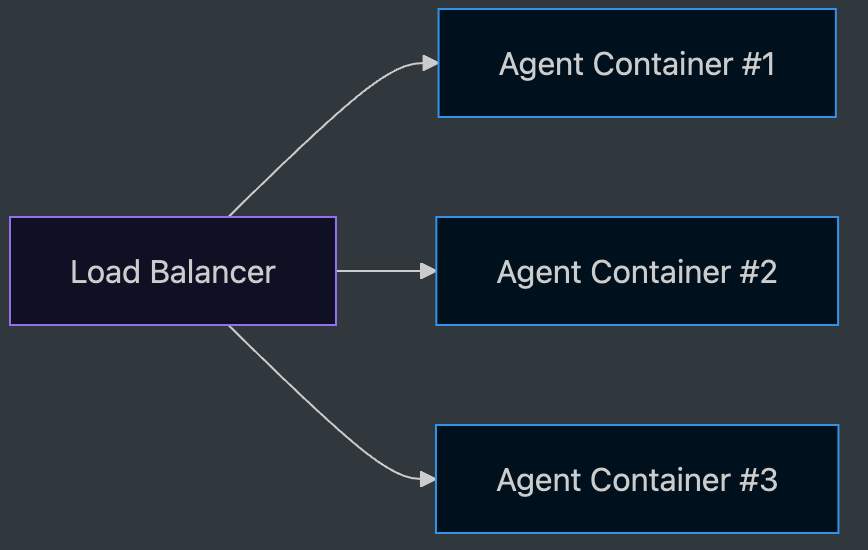
The LB scatters incoming requests across multiple containers. Whichever container receives it, it must operate identically. If one container is busy, it must route to another, and if a temporary failure like 429 throttling occurs, it must retry. For this to be possible, there must be no differences between containers.
Then, if containers are constantly being created and destroyed, how do we make it look to the user as if the Agent is always alive?
We keep the containers stateless. Since they do not hold sessions, they operate identically regardless of which container receives the request. The lifecycle of a session is maintained outside the container. It is placed in external memory and handed over via an identifier. Even if the container dies and comes back to life, the session does not die.
This chapter is about what happens inside the container. While keeping the container stateless, how do we absorb the expensive initialization costs inside it?
Let’s clarify the terminology first. A Session is the conversation history and its identifier stored in external memory. An Agent Object is an instance created by the SDK for every request. The two have different lifecycles.
Keeping a Fresh Agent Object Every Time
A container receives requests from multiple users. However, an Agent object (e.g., Strands Agent) carries request-level states like message history, tool execution results, and hook states as instance fields. If the traces of one request remain in the object and the next request grabs the same object, conversations from different users will be mixed up. Therefore, the Agent object must be freshly initialized for every request.
However, creating it anew every time is inefficient.
If everything is newly created for every request, the response slows down. LLM Clients and Tool Clients, in particular, have expensive init costs: Authentication, connection pools, and MCP handshakes.
To minimize this cost, the LLM client and the clients used by tools (MCP, API, etc.) are cached. Since the Client only holds authentication and connections, and does not hold state that shouldn’t be shared across requests (conversation, tool results), it is safe to reuse. In summary, objects that hold state are newly created for each request, and objects that do not hold state are reused.
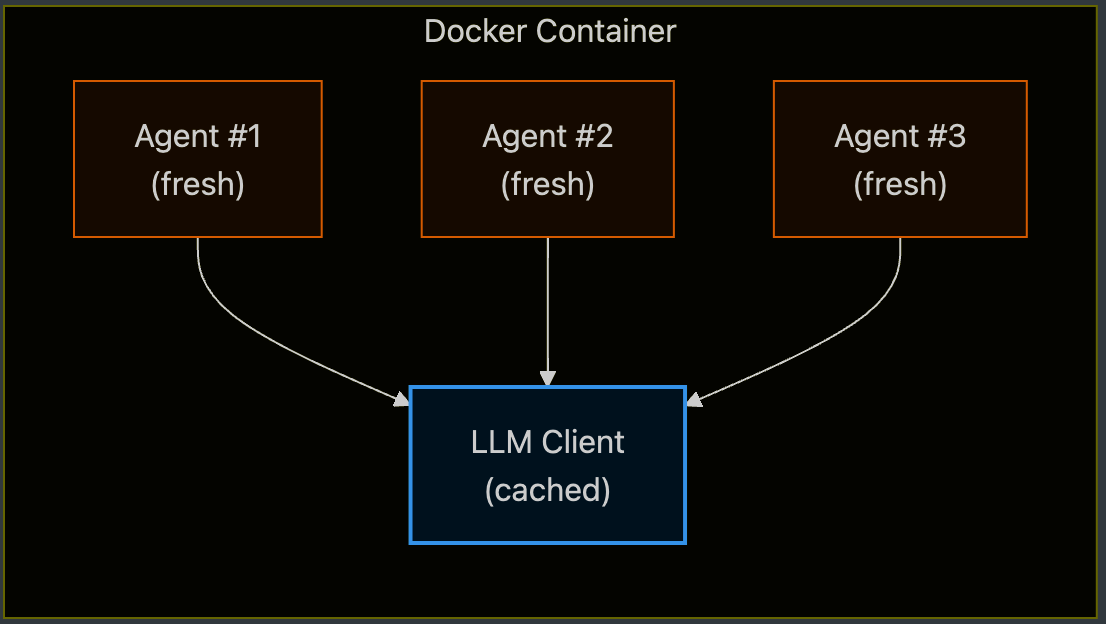
Translated into code, it might look like this.
# Module-level: initialized once per container, reused across requests
_llm_client: LLMClient | None = None
_mcp_clients: dict[str, MCPClient] = {}
def get_llm_client() -> LLMClient:
global _llm_client
if _llm_client is None:
_llm_client = LLMClient(...) # auth, connection pool
return _llm_client
def get_mcp_client(name: str) -> MCPClient:
if name not in _mcp_clients:
_mcp_clients[name] = MCPClient(...) # handshake
return _mcp_clients[name]
# Per-request: fresh Agent every time
def handle_request(request):
session = load_session(request.session_id) # from external memory
agent = Agent(
client=get_llm_client(), # cached (warm)
tools=[get_mcp_client("search")], # cached (warm)
messages=session.messages, # injected per request
)
return agent.run(request.message)
The Client is created once at the module level and reused per request. The Agent is built freshly on the spot, but it receives the session.messages read from external memory to inherit the continuity of the conversation.
Then wait, where is the conversation continuity that the user sees? The Agent object is fresh every time. The answer is outside the container. External memory holds the session, and the new Agent object reads it for every request and injects it into the system prompt or message history. In other words, the Agent object is stateless, and the session is stateful externally. How this external memory is operated will be covered in Part 2.
The effect of this approach is consolidating the cold init to once per container. The first requesting user experiences the client init (authentication, connection pool, MCP handshake) as is, but from then on, all requests received by that container go to the already created client, that is, the warm path. The average latency might not seem much different when traffic is low, but it’s a different story under load. If cold init occurs for every request, connection pool contention and CPU utilization skyrocket, and the p99 degrades. Caching groups that cold path to once per container lifetime, thereby boosting the sustainable RPS per container.
Checking the Availability Status of the Agent
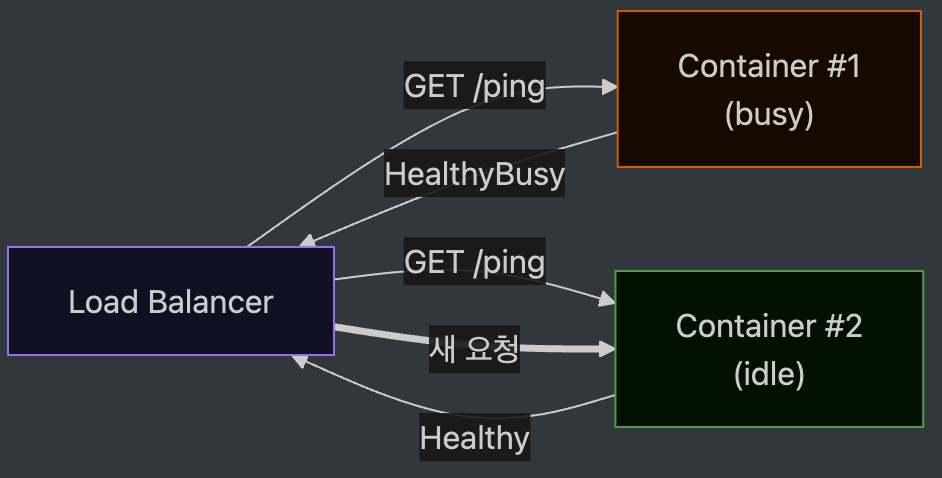
Even if you scale up containers statelessly, it’s meaningless unless you send requests to places that can accept them. The LB must know which container can handle the request right now. This is because it could send another request to a container that is already processing one.
If one Agent container is doing reasoning that takes over 10 seconds, and the LB doesn’t know the Agent’s status, it might route a new request to the same container again. Then the queue builds up, and a timeout occurs.
Therefore, a health check is not “Are you alive?” but “Can you process a request right now?”
Conventional health checks are simple. If the process is up, it’s OK. But from the perspective of an Agent container, that’s not enough. Even if it’s up, if it’s currently processing, it’s better not to accept new requests. The container must know its own in-flight status, and it must expose this information so the LB can read it.
We solved the problem by placing an in-flight counter inside the container, and having the /ping handler check that value to change the response. A busy signal like Healthy if idle, or HealthyBusy if processing. Managed environments like the AgentCore Runtime read this signal to route new requests to other idle containers. In a standard Docker environment, you can achieve the same effect by toggling the readiness probe or rejecting with a 503 when the concurrency limit is reached.
Without a busy signal, the LB cannot see inside the container. It only sees the health check pass and sends more requests to processing containers, while neighboring containers sit idle. Even if you increase the instances, traffic skews to one side, and the p99 remains the same. A busy signal must be included so the LB can pick and send only to containers that can accept it. Even if one container holds a long task, new requests flow to other containers in the meantime. The number of instances directly translates to throughput. And on this premise, the caching from Point 1 also accumulates its effect. Requests must be evenly distributed so that each container can go through the cold path just once and be done.
Handling Throttling
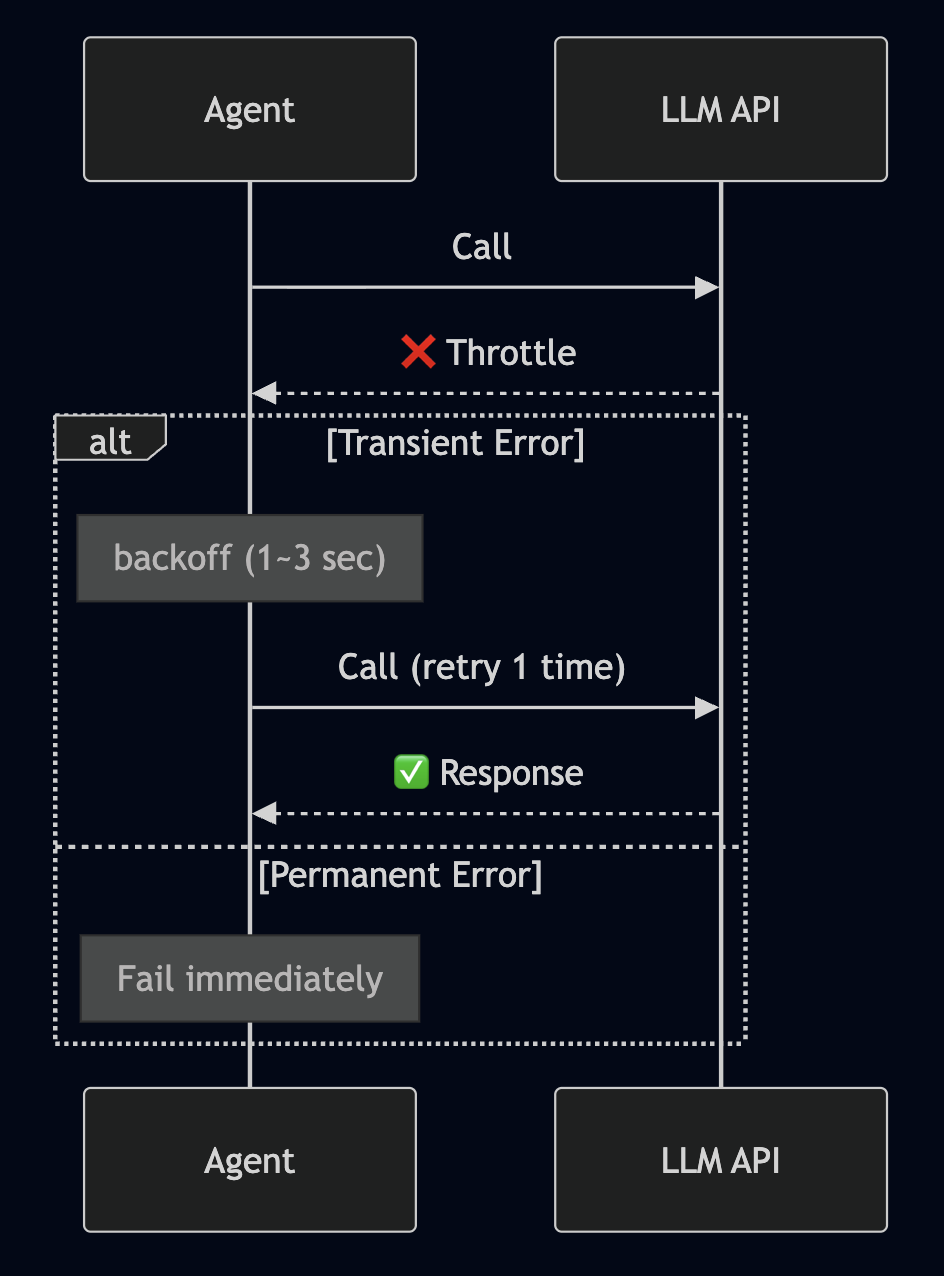
The most common thing encountered in LLM APIs is throttling. If you hit the TPM/RPM quota, or if concurrent requests flood in, a ThrottlingException is thrown.
Here, statelessness provides a bonus. Because the Agent is made stateless, it is safe to send the same request again. Without duplicate effects, the same input leads to the same result. An environment where retries are meaningful has been created.
Not all errors are retried.
Blindly retrying is dangerous. Retrying even permanent errors just wastes time, and putting infinite retries on throttles kills neighboring requests as well (thundering herd). So, errors are divided into two types.
Transient errors are retried only 1 to 2 times after a backoff. Things like throttles, transient 5xx, and temporary network issues. Jitter is mixed in so they don’t cluster at the same time. Permanent errors are failed immediately. Things like authentication, validation failures, and content filtered will just yield the same result even if retried. It’s better to return it to the user quickly.
Transferred to code, it looks like this. Based on the Strands Agent, retry policies are injected via a hook.
class TransientErrorRetryHook:
MAX_RETRIES = 2
def on_error(self, exc, attempt):
if attempt >= self.MAX_RETRIES:
raise exc
if is_transient(exc):
sleep(backoff_with_jitter(attempt)) # e.g., 1s, 3s + random
return RETRY
raise exc # permanent error → propagate immediately
def is_transient(exc):
# transient: throttle, transient 5xx, network blip
return isinstance(exc, (ThrottlingException,
ServiceUnavailableException,
ConnectionError))
# permanent (not classified): AuthError, ValidationError, ContentFilteredError → raise
The point is two lines. Divide with is_transient, and only use jittered backoff for transients 1 to 2 times.
Conclusion
The three points ultimately branch out from one single decision: Do not keep state in the container. This single line enables client caching inside the container, LB routing between containers, and safe retries outside the container. The operational details of a distributed system usually work like this. One grand principle works in different shapes across various places.
But if the container does not hold state, the state must be somewhere. Because the continuity of the conversation seen by the user doesn’t disappear. That place postponed as “external memory” throughout Part 1, how the session survives outside the container, is the topic of Part 2. What is placed in which memory, how the conversation withstands when the memory shakes, and the reality of operating Agent memory in a distributed environment will be covered.