Building an AWS-Based RAG Pipeline
The Generational AI Blind Spot
We’ve got a fantastic new AI coding assistant, but when you ask it about your company’s proprietary service architecture, it gives you a generic shrug (or worse, a confident hallucination). Why? Because our AI lives on the general internet, and our team’s hard-won knowledge is locked behind firewalls and scattered across tools like Confluence, Slack, and internal documentation.
This is a pain point for everyone. As a service developer, we need that agent to understand the nuance of our codebase and team conventions. As a service operator, we can’t afford to waste time retracing the steps of a solved production issue - we need the fastest, most reliable fix, instantly.
If you’re interested in how to systematically manage context for AI coding assistants, check out my series on context management with Kiro.
User Stories
- As a service developer, I want to provide context to my coding agent based on the knowledge my team possesses.
- As a service operator, I want to find the right and shortest path to solving similar issues my team has previously encountered.
The Power of Retrieval Augmented Generation (RAG)
The bridge between general LLM intelligence and specific team expertise is Retrieval Augmented Generation (RAG). This article details the construction of a robust, AWS-based RAG pipeline designed to eliminate those “blind spots.” I’ll walk you through the entire ETL process - extracting changes every six hours, cleaning sensitive info with Comprehend, and indexing for code structure (Neptune) and semantics (OpenSearch).
Our goal is simple: to create an AI agent that is not only intelligent but institutionally smart, giving software developers the right context to AI agents.
Architecture the RAG Data Pipeline
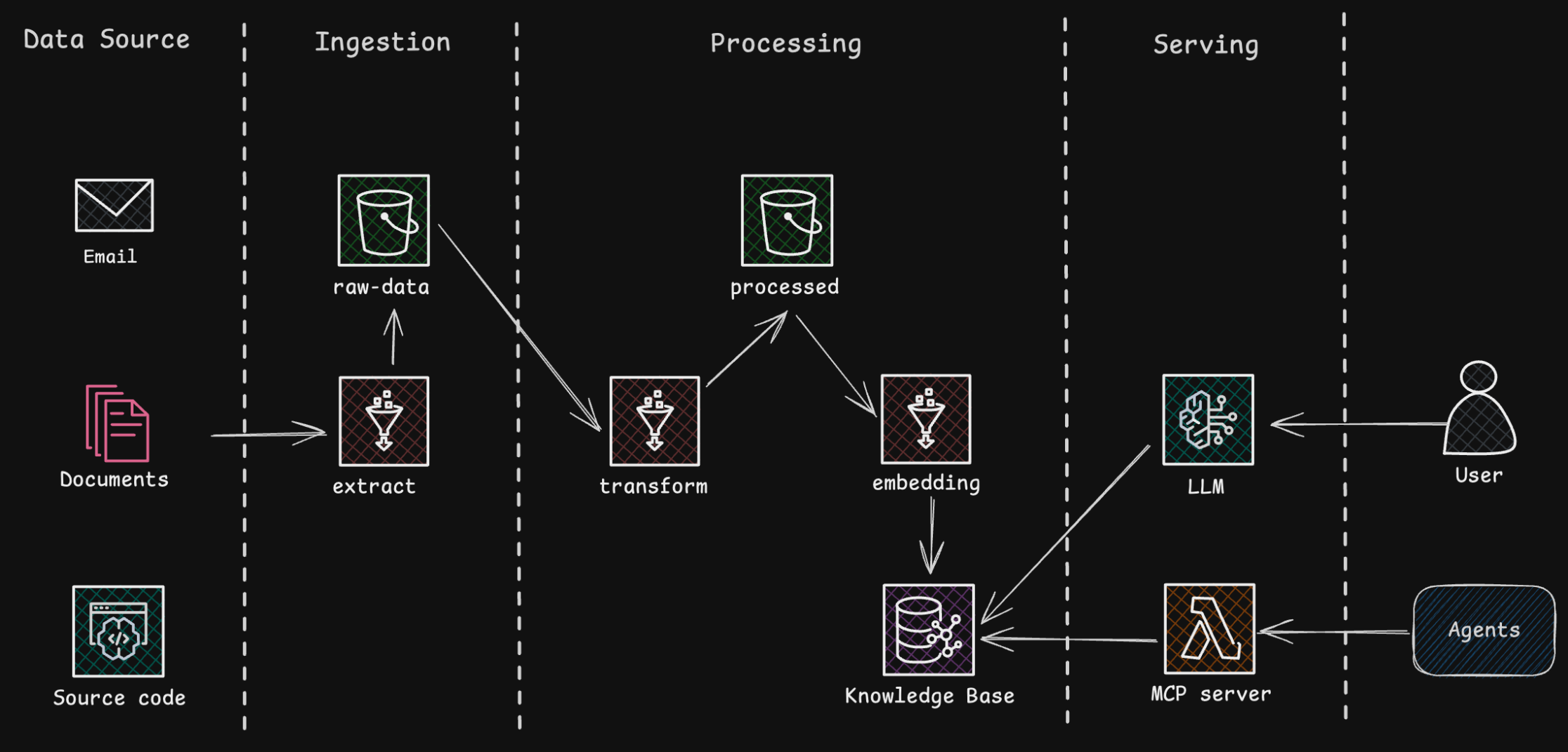
Building a RAG system that delivers high-quality, up-to-date answers requires a disciplined and automated data pipeline. Our AWS-based RAG system is designed to periodically collect diverse internal materials - from wikis to Slack threads - and process, embed, and index them for the question answering engine.
The core of this system is an ETL (Extract, Transform, Load) workflow, triggered every six hours by AWS Step Functions or whenever the source data is updated.
- Extract: Changes are incrementally synced from diverse data sources and saved to an S3 raw-data bucket.
- Transform/Process: Sensitive information (like PII) is detected and masked using Amazon Comprehend. Document formats are standardized and saved to an S3 processed-data bucket.
- Load/Index: Embeddings are generated, and the data is indexed in two places: Amazon OpenSearch Service for vector search and Amazon Neptune for code structure and relational information. If you’d like to see what these two databases can do, check out this article on context management.
Data Sources and Incremental Ingestion
The ingestion stage focuses on efficiency by only processing what has changed. We pull from everywhere: internal wikis (Confluence, SharePoint), documents (Word/PDF), and collaboration tools (Slack/Teams message threads).
To handle large datasets efficiently, AWS Step Functions and Lambda functions/AWS Glue jobs are scheduled (via EventBridge) to incrementally sync only the content that has been changed or newly created since the last collection. This is critical for keeping the knowledge base fresh without wasting resources. We use APIs (like Confluence or Slack) to fetch content and store the results in an S3 raw-data bucket.
Preprocessing and Transformation for Quality
The quality of your RAG answer is directly proportional to the quality of your source documents. This stage ensures a clean, consistent knowledge base.
- Filtering and Cleansing: We use Amazon Comprehend’s PII detection to automatically identify and mask sensitive items (names, emails) before they’re embedded.
- Format Standardization: We convert various formats (Word, PDF) into plain text using tools like AWS Textract.
- Chunking: For optimal retrieval, the cleaned content is split into smaller, meaningful chunks (typically 200–500 tokens). Each chunk gets a unique ID and reference metadata, which is stored in the S3 processed-data bucket.
Dual Indexing: Vectors and Graphs
Effective RAG often requires more than just semantic similarity. By using two specialized databases, we can enrich the context with both meaning and structure.
- Embedding Generation: We call models like Titan Text Embeddings models via Amazon Bedrock to generate the vector embedding for each document chunk.
- Vector DB (Semantic Search): The generated embedding vectors are stored in the k-NN vector index of Amazon OpenSearch Service. This enables real-time vector search to find the most semantically similar document chunks relevant to the user’s query.
- Graph DB (Structural Search): Content with relationships - like source code, configuration files, or relational data - is stored in Amazon Neptune. This allows the RAG query to perform a knowledge graph query to retrieve associated entities, enriching the context with structural understanding.
Query Processing and Serving
This is where the user’s question becomes a relevant, cited answer.
- Query Reception (MCP server): The query hits an AWS API Gateway endpoint, which is forwarded to a backend Lambda function.
- RAG Retrieval: The Lambda function calls the Bedrock RAG API (/retrieveAndGenerate). It retrieves the top $k$ similar chunks from OpenSearch and simultaneously queries Neptune for additional structural context.
- Response Generation: All of this retrieved context (the document text chunks and key entity information) is passed in a single prompt to Claude Sonnet 4.5 (Actually, you can use any LLM you want). The model synthesizes this evidence and the original question to formulate the final response. The response must include the source of information to ensure trustworthiness.
The Evolution of Context Engineering
We’re still iterating to find the optimal way to develop a highly accurate agent. There will always be a gap when it comes to fully keeping up with human context and nuance. However, by defining tasks, breaking them into manageable units, and building a team-specific knowledge base that serves as a context engine, we can continuously evolve our agents to be more accurate, more reliable, and ultimately, more valuable to the developers and operators who rely on them.